
Study Notes for Postgrest Starter Kit
postgrest is an alternative to GrapqQL. It generates and serves REST APIs from a Postgres database automatically.
Table of Contents
postgrest is an alternative to GrapqQL. It generates and serves REST APIs from a Postgres database automatically.
postgrest starter kit is a handy starter kit and tooling to produce production ready applications on top of postgrest.
The official documentations of postgrest and psk (postgrest starter kit) are very high quality. In this blog post, I follow the tutorial steps already explained in these documents.
Installation and Setup
$ git clone --single-branch https://github.com/subzerocloud/postgrest-starter-kit khumbuicefall
$ cd khumbuicefall
Edit .env
COMPOSE_PROJECT_NAME=khumbuicefall
Run the server embedded in docker container:
$ docker-compose up -d # wait for 5-10s before running the next command
Install and run [subzero-cli] to see what is going inside (optional):
$ docker pull subzerocloud/subzero-cli-tools
$ npm install -g subzero-cli
$ subzero dashboard
Basic REST Calls
$ curl http://localhost:8080/rest/todos?select=id
[{"id":1},{"id":3},{"id":6}]
Make an authorized request
$ export JWT_TOKEN=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxLCJyb2xlIjoid2VidXNlciJ9.uSsS2cukBlM6QXe4Y0H90fsdkJSGcle9b7p_kMV1Ymk
$ curl -H "Authorization: Bearer $JWT_TOKEN" http://localhost:8080/rest/todos?select=id,todo
[{"id":1,"todo":"item_1"},{"id":3,"todo":"item_3"},{"id":6,"todo":"item_6"}]
Update Sample Data
Update the initial sample data and check if it is updated in the database:
Edit db/src/sample_data/data.sql:
1 item_1 FALSE 1
->
1 item_1_updated FALSE 1
Run request again:
$ curl -H "Authorization: Bearer $JWT_TOKEN" http://localhost:8080/rest/todos?select=id,todo
[{"id":1,"todo":"item_1_updated"},{"id":3,"todo":"item_3"},{"id":6,"todo":"item_6"}]
Check Generated SQL Using subzero
subzero is a monitoring tool. It shows the internal logs of openresty, rabbitmq, postgres, and postgrest.
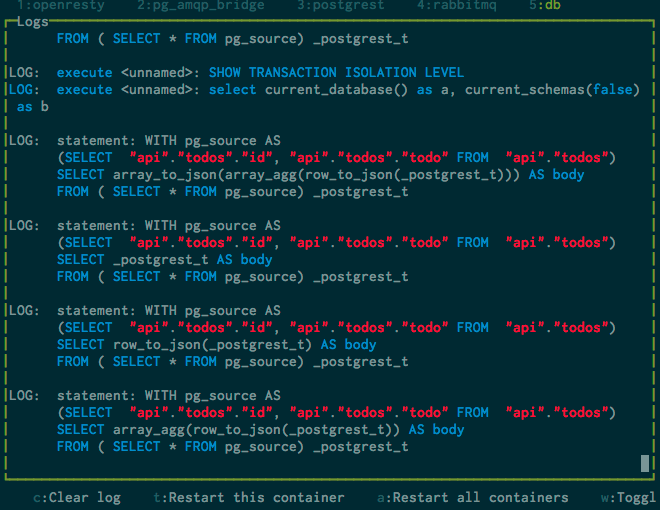
$ curl http://localhost:8080/rest/todos?select=id
The following SQL code is generated automatically by postgrest:
WITH pg_source AS
(SELECT "api"."todos"."id" FROM "api"."todos")
SELECT
null AS total_result_set, pg_catalog.count(_postgrest_t) AS page_total, array[]::text[] AS header, coalesce(array_to_json(array_agg(row_to_json(_postgrest_t))), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
+--------------------+--------------+----------+------------------------------+
| total_result_set | page_total | header | body |
|--------------------+--------------+----------+------------------------------|
| <null> | 3 | [] | [{"id":1},{"id":3},{"id":6}] |
+--------------------+--------------+----------+------------------------------+
Let’s return both id and todo attributes:
$ curl -H "Authorization: Bearer $JWT_TOKEN" http://localhost:8080/rest/todos?select=id,todo
WITH pg_source AS
(SELECT "api"."todos"."id", "api"."todos"."todo" FROM "api"."todos")
SELECT null AS total_result_set, pg_catalog.count(_postgrest_t) AS page_total, array[]::text[] AS header, coalesce(array_to_json(array_agg(row_to_json(_postgrest_t))), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
+--------------------+--------------+----------+--------------------------------------------------------------------------------------+
| total_result_set | page_total | header | body |
|--------------------+--------------+----------+--------------------------------------------------------------------------------------|
| <null> | 3 | [] | [{"id":1,"todo":"item_1_updated"},{"id":3,"todo":"item_3"},{"id":6,"todo":"item_6"}] |
+--------------------+--------------+----------+--------------------------------------------------------------------------------------+
In order to understand this code, I simplified it to its core:
WITH pg_source AS
(SELECT "api"."todos"."id", "api"."todos"."todo" FROM "api"."todos")
SELECT _postgrest_t AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
+--------------------+
| body |
|--------------------|
| (1,item_1_updated) |
| (3,item_3) |
| (6,item_6) |
+--------------------+
Adding row_to_json function:
WITH pg_source AS
(SELECT "api"."todos"."id", "api"."todos"."todo" FROM "api"."todos")
SELECT row_to_json(_postgrest_t) AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
+----------------------------------+
| body |
|----------------------------------|
| {"id":1,"todo":"item_1_updated"} |
| {"id":3,"todo":"item_3"} |
| {"id":6,"todo":"item_6"} |
+----------------------------------+
Adding array_agg function:
WITH pg_source AS
(SELECT "api"."todos"."id", "api"."todos"."todo" FROM "api"."todos")
SELECT array_agg(row_to_json(_postgrest_t)) AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
+----------------------------------------------------------------------------------------------+
| body |
|----------------------------------------------------------------------------------------------|
| ['{"id":1,"todo":"item_1_updated"}', '{"id":3,"todo":"item_3"}', '{"id":6,"todo":"item_6"}'] |
+----------------------------------------------------------------------------------------------+
Adding array_to_json function:
WITH pg_source AS
(SELECT "api"."todos"."id", "api"."todos"."todo" FROM "api"."todos")
SELECT array_to_json(array_agg(row_to_json(_postgrest_t))) AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
+--------------------------------------------------------------------------------------+
| body |
|--------------------------------------------------------------------------------------|
| [{"id":1,"todo":"item_1_updated"},{"id":3,"todo":"item_3"},{"id":6,"todo":"item_6"}] |
+--------------------------------------------------------------------------------------+
postgrest returns JSON formatted data by default. It looks like this is done by these three function calls: array_to_json(array_agg(row_to_json(...)))
Check Database Logs
When I make any change in any of the watched *.sql files, psk automatically detects the change event and reruns all these *.sql files from scratch. I can see what is going on from the logs inside subzero.
To see the logs clearly, I first ran c: Clear Log inside subzero. Then, I made an editing inside db/src/data/todo.sql. That generated the following logs:
./db/src/data/todo.sql changed
Starting code reload ------------------------
LOG: statement: SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'app';
FATAL: terminating connection due to administrator command
LOG: statement: DROP DATABASE if exists app;
LOG: statement: CREATE DATABASE app;
Ready ---------------------------------------
LOG: statement: set client_min_messages to warning;
todo.sql script is imported (or included) from db/src/data/schema.sql
\ir todo.sql
db/src/data/schema.sql script is imported from db/src/init.sql
\ir data/schema.sql
The first visible line in init.sql is:
set client_min_messages to warning;
So, it looks like the above log messages after Ready ---- line come from init.sql. Prior statements are somehow handled by psk or postgrest.
File Structure of .sql Files
init.sql file contains several include i.e. \ir statements such as:
\ir data/schema.sql
\ir api/schema.sql
\ir authorization/roles.sql
\ir authorization/privileges.sql
\ir sample_data/data.sql
.sql files are separated into 4 folders: data, api, authorization, sample_data.
data folder contains schema definition commands such as CREATE TABLE
api folder contains view definition commands such as CREATE VIEW
authorization folder contains role and privilege definition commands such as CREATE ROLE
sample_data folder contains actual sample data commands such as INSERT or COPY
General logical structure of calling these .sql files is the same. For example, init.sql imports data/schema.sql. Then data/schema.sql file imports all the remaining .sql files inside data/ folder.
Creating New Table and Sample Data
Create db/src/data/tables01.sql and put the CREATE TABLE statements inside:
create table client (
id serial primary key,
name text not null,
address text,
user_id int not null references "user"(id),
created_on timestamptz not null default now(),
updated_on timestamptz
);
create index client_user_id_index on client(user_id);
Edit db/src/data/schema.sql to import this new file:
\ir todo.sql
\ir tables01.sql
Now, create db/src/api/views_and_procedures01.sql and put CREATE VIEW statements inside:
create or replace view clients as
select id, name, address, created_on, updated_on from data.client;
Edit db/src/api/schema.sql to import this new file:
\ir todos.sql
\ir views_and_procedures01.sql
Edit db/src/sample_data/data.sql to add the following lines:
set search_path = data, public;
\echo # filling table client (3)
COPY client (id,name,address,user_id,created_on,updated_on) FROM STDIN (FREEZE ON);
1 Apple address_1_ 1 2017-07-18 11:31:12 \N
2 Microsoft address_1_ 1 2017-07-18 11:31:12 \N
3 Amazon address_1_ 2 2017-07-18 11:31:12 \N
\.
--
ALTER SEQUENCE client_id_seq RESTART WITH 4;
--
ANALYZE client;
Edit db/src/sample_data/reset.sql and add this line before COMMIT:
truncate data.client restart identity cascade;
Now, after saving all these files, init.sql is automatically called by psk and all the new tables, views, and sample data are created. Check in psql:
app=# set search_path = data, public;
SET
app=# \dt
List of relations
Schema | Name | Type | Owner
--------+--------+-------+-----------
data | client | table | superuser
data | todo | table | superuser
data | user | table | superuser
(3 rows)
Edit db/src/authorization/privileges.sql and add GRANT privilege statements:
grant select, insert, update, delete
on api.clients
to webuser;
Note that, api.clients refers to the view api.clients not to the table data.client.
Now, make a REST API call:
$ curl -H "Authorization: Bearer $JWT_TOKEN" http://localhost:8080/rest/clients?select=id,name
[{"id":1,"name":"Apple"},{"id":2,"name":"Microsoft"},{"id":3,"name":"Amazon"}]
In this section, I defined only one table client. The actual tutorial creates additional tables such as project, task etc.
